记一次 Pilot 推送性能的优化过程
背景及问题
最近在落地 ServiceMesh 的过程中,遇到了一个 Istio 控制面 Pilot 下发 xDS 配置过慢的性能问题,背景如下:
集群环境中 ServiceEntry、DestinationRule、VirtualService、WorkloadEntry 数目均为 2200 左右,当测试脚本模拟服务实例上下线时,监测数据面日志发现 MOSN 获取 xDS 配置较慢,大部分配置从服务开始变动到数据面收到 xDS 推送时间均在 1m20s 左右。
测试脚本大部分操作为单个服务实例的上下线,按道理 EDS 增量推送下发配置应该很快。遂开始排查具体原因。
问题排查
首先用 pprof 分析 CPU 使用时间,命令如下:
$ go tool pprof -http 127.0.0.1:8089 http://[istio-pod-ip]:8080/debug/pprof/profile\?second\=600 |
分析结果如图:
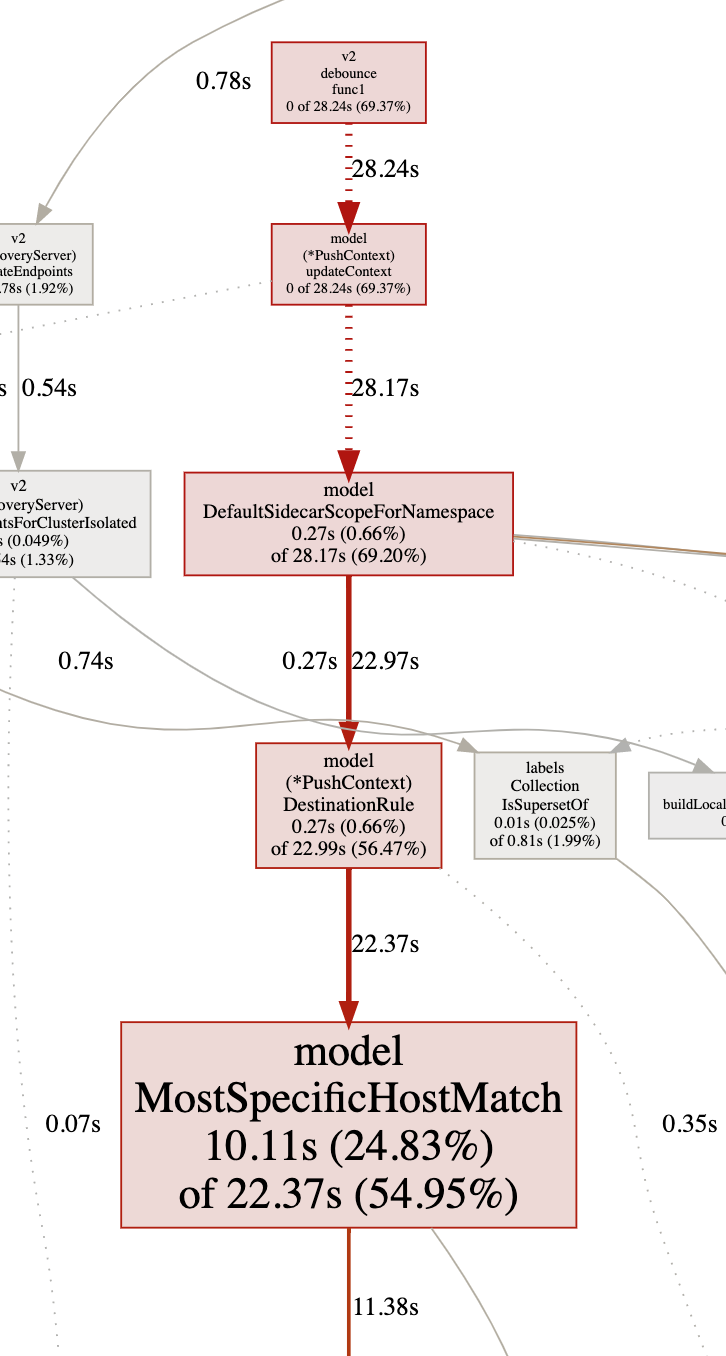
可以看到时间大部分都花在防抖函数 debounce 中。进一步分析发现时间主要花在了 initPushContext 中。debounce 这里做推送主要分为两部分,一个是 ADS ,另一个为 EDS 增量下发。这里主要原因是因为实际的 Push() 函数在做全量推送时初始化 PushContext 过慢,导致 free 一直未释放,后续的 PushRequest 一直被合并,每当延时器 timeChan 工作时发现 free 未释放导致一直顺延。
相关 debounce 代码片段如下:
for { |
这里可以看到在调用 push() 的时候必须等 pushFn(req) 完成后才会释放 free :
push := func(req *model.PushRequest) { |
为什么 Push() 这么慢呢?主要是在 req.Full 做全量推送的时候,需要初始化 PushContext ,初始化 PushContext 的过程中初始化了 SidecarScope ( pprof 分析是创建默认 SidecarScope 的地方慢了 ):
// Must be initialized in the end |
当 ServiceEntry 、 DestinationRule 、 VirtualService 、 Sidecar 发生变化都会触发 initSidecarScopes 。
Sidecar 有两种,一种是带 WorkloadSelector 的,一种是不带的。不带 Selector 的话就是对这个命名空间所有服务生效。如果没有手动创建默认的 Sidecar ,Pilot 会通过 DefaultSidecarScopeForNamespace 为当前命名空间创建一个默认的 Sidecar ,他会将网格中所有的服务都遍历一遍,写入 SidecarScope 中。
这就是慢的地方。创建默认的 Sidecar 有两个循环,第一个是:
// DefaultSidecarScopeForNamespace is a sidecar scope object with a default catch all egress listener |
这个 out.services 的数目在 8000 ~ 9000 个,因为我们 ServiceEntry 的数目大概在 2200 个,在定义 VirtualService 的时候定义了 3 个 HttpMatch ,也就是蓝绿灰分组,再加上一个兜底的默认 Match ,总共是 4 个 HttpMatch ,这在生成 Pilot 定义的 Service 时每个 subset 都会定义一个,即每个服务会有 4 个 Service,其实这个 Service 数目对应就是 xDS 中的 cluster 的数目。所以这一层循环是 8000~9000 次。
再一层的循环就是 ps.DestinationRule 中的 MostSpecificHostMatch ,也是 pprof 提示的地方,这里又把当前命名空间所有的 DestinationRule 都传进来做了一次遍历:
// MostSpecificHostMatch compares the elements of the stack to the needle, and returns the longest stack element |
所以这两次粗略计算共遍历了 8000 * 2000 = 16000000 次,而这些遍历是在做什么呢?做的是字符串的匹配操作:
func (n Name) IsWildCarded() bool { |
优化思路
分析到慢的原因,就可以因地制宜想出解决的办法了:
为每个集群创建默认的 SidecarScope
包括创建
rootNsSidecarConfig,更精细化的管理SidecarScope,避免使用 Pilot 的DefaultSidecarScopeForNamespace方法遍历所有服务。减少 Pilot 中无效的 cluster
目前 Pilot 生成的 cluster 大概是 8000 ,但真正有实例的 cluster 大概 2000 左右,可以想办法把那些没有 endpoint 的实例砍掉。当实例变化时去掉 VirtualService 中多余的 match 。如只有蓝组则去掉绿组灰组的配置,避免创建空的 cluster 徒增计算成本。
在者就是调整默认 VirtualService 的结构,默认的是所有服务都会创建蓝绿灰三组 subset ,在 VirtualService 中的策略为蓝走蓝,绿走绿,灰走灰,这些默认策略在生成前也应该判断当前的 subset 有没有实例,没有实例就不创建对应的 match 了。
关闭 EDS 的防抖,使 EDS 实时下发配置,不用初始化 PushContext
目前的情况是为服务的变化(如 ServiceEntry 和 VirtualService)做的全量推送时,初始化
PushContext的时候 hang 住了 EDS 的推送,因为 EDS 默认是走防抖的,所以一直被Merge。因为free一直没有被释放,所以当timeChan调用PushWorker的时候一直跳过,我们应该不能让服务的推送 hang 住实例的推送。需要关闭 EDS 的防抖,不过对 Pilot 和数据面的 CPU 资源可能占用较多。
for { |
关闭 EDS 防抖参数的说明:EnableEDSDebounce = env.RegisterBoolVar( |
优化 Pilot 的防抖及节流参数
如果集群中 Pilot 单独使用了一台或几台性能很高的节点,可以将节流参数
PILOT_PUSH_THROTTLE调高一点,追求推送速度的话可以调低防抖的PILOT_DEBOUNCE_MAX时间(不过像本文防抖被 Push hang 住了调整这个参数没什么作用),PILOT_DEBOUNCE_AFTER时间也可以调小一些,可以让变化实时生效。不过这些参数还是要根据实际情况做一些平衡,以为追求实时推送也会为控制面带来不必要的压力,反倒降低了整体的推送效率。